 Wir suchen ständig neue Tutorials und Artikel! Habt ihr selbst schonmal einen Artikel verfasst und seid bereit dieses Wissen mit der Community zu teilen? Oder würdet ihr gerne einmal über ein Thema schreiben das euch besonders auf dem Herzen liegt? Dann habt ihr nun die Gelegenheit eure Arbeit zu veröffentlichen und den Ruhm dafür zu ernten. Schreibt uns einfach eine Nachricht mit dem Betreff „Community Articles“ und helft mit das Angebot an guten Artikeln zu vergrößern. Als Autor werdet ihr für den internen Bereich freigeschaltet und könnt dort eurer literarischen Ader freien Lauf lassen.
Wir suchen ständig neue Tutorials und Artikel! Habt ihr selbst schonmal einen Artikel verfasst und seid bereit dieses Wissen mit der Community zu teilen? Oder würdet ihr gerne einmal über ein Thema schreiben das euch besonders auf dem Herzen liegt? Dann habt ihr nun die Gelegenheit eure Arbeit zu veröffentlichen und den Ruhm dafür zu ernten. Schreibt uns einfach eine Nachricht mit dem Betreff „Community Articles“ und helft mit das Angebot an guten Artikeln zu vergrößern. Als Autor werdet ihr für den internen Bereich freigeschaltet und könnt dort eurer literarischen Ader freien Lauf lassen.
| Permutationen |
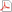 |
 |
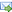 |
| Geschrieben von: Kristian | ||||
| Freitag, den 23. September 2005 um 19:26 Uhr | ||||
EinführungUnter einer Permutation versteht man in der Mathematik die Veränderung der Reihenfolge der Elemente einer Menge. Zum Beispiel kann die Permutation eines bestimmten strings bei der Suche nach einem Passwort, wessen Buchstaben zwar bekannt sind nicht aber deren Reihenfolge, ganz nützlich sein. Eine Permutation ist mathematisch gesehen eine bijektive Abbildung einer endlichen Menge mit n Elementen auf sich selbst  Permutationen spielen nicht nur in der reinen Kombinatorik eine wichtige Rolle sondern finden auch in der Spieleentwicklung Verwendung. Darunter zum Beipiel bei der Matrizenberechnung von geometrischen Figuren. Permutation ohne WiederholungBei der Permutation ohne Wiederholung müssen folgende Voraussetzungen erfüllt sein:
Die Berechnung erfolgt über die Fakultätsbildung  Nehmen wir als Beispiel die folgende Situation an. Ein Einbrecher benötigt zum Öffnen einer durch ein Kombinationsschloß verriegelten Türe einen Code. Nach gründlicher Spurensuche findet er heraus, das sich auf dem Schloss nur auf vier Tasten Fingerabdrücke befinden. Nämlich auf Taste 3, 4, 5 und 8. Außerdem weiß er das beim Codeschloß mit der Seriennummer 25F7-ST66 ein 4-stelliger Zugangscode in der richtigen Reihenfolge eingegeben werden muss. Die Frage lautet nun, wieviele Kombinationen muss unser Einbrecher durchgehen um das Schloß zu knacken und welche sind das?  Wie bereits oben erläutert errechnet sich die Anzahl der möglichen Kombinationen aus der Fakultät. Somit ergeben sich für vier unterschiedliche Elemente aus der Menge P insgesamt 24 Permutationen. Nachfolgend sind diese vollständig gelistet: 3458, 3485, 3548, 3584, 3845, 3854, 4358, 4385, 4538, 4583, 4835, 4853, 5348, 5384, 5438, 5483, 5834, 5843, 8345, 8354, 8435, 8453, 8534, 8543. Nun ist das Ganze für vier Zahlen (Elemente) noch sehr überschaubar und die 24 verschiedenen Permutationen lassen sich problemlos in kurzer Zeit durchdenken. Doch aufgrund des Wachstumsverhaltens von n! steigt die Anzahl an möglichen Permutationen ab 5 Elementen sehr stark an und erreicht bereits für n=69 eine Zahl mit unglaublichen 99 Dezimalstellen! Deshalb wäre es gut ein Programm zu haben welches uns die Aufgabe der Berechnung abnimmt. Die C++ Standard Bibliothek mit ihren mächtigen Algorithmen stellt uns hierfür die Funktionen prev_permutation und next_permutation zur Verfügung. Diese sind in der STD Header-Datei algorithm versammelt. Der Algorithmus prev_permutation generiert für den Bereich [first, last] alle vorhergehenden Permutation der Elemente, während next_permutation dies für alle nachfolgenden macht. Geordnete ElementeBeachten sie das der STL Algorithmus davon ausgeht dass alle Elemente lexikographisch geordnet vorliegen! Existiert eine vor-/nachfolgende Permutation wird true zurückgegeben. Das untere Programm erzeugt für die Buchstaben A, B und C insgesamt sechs Permutationen. // Calculate Permutations - using STL Algorithms #include <iostream> #include <algorithm> int main() { char f[] = { 'A', 'B', 'C' }, *const fn = f + sizeof(f) / sizeof(*f); unsigned int i = 0; do { std::cout << ++i << ". Permutation: "; copy(f, fn, std::ostream_iterator<char>(std::cout, " ")); std::cout << std::endl; } while(std::next_permutation(f, fn)); return 0; } Der Algorithmus aus der STL generiert alle nachfolgenden Permutationen für die Elemente A, B, und C die in Frage kommen und gibt diese auf den Bildschirm aus. Ungeordnete ElementeWie lässt sich der Algorithmus nun auch bei lexikographisch ungeordneten Wörtern (Elementen), wie z.B. monkey verwenden? Vielleicht können sie es sich schon denken!? Wir müssen den string einfach nur ordnen lassen bevor wir diesen an die STL Funktion übergeben.
Wir benutzen dafür die STL Funktion stable_sort(). Im Durchschnitt ist die auf Qicksort basierende sort() Funktion zwar etwas schneller, kann aber unter Umständen das Laufzeitverhalten des Programms negativ beeinflußen. Werfen wir nun einmal einen Blick auf die veränderte Funktion mit dem neuen Namen SSTL_Permutation: // ============================================================================ // Function: SSTL_Permutation // Description: Generate all permuted strings for an input string using // original STL function next_permutation(). // Parameter: @input: the input string. // @result: the buffer, where permutations are stored // Note: STL next_permutation permutes the string input to the // lexicographically next string as an arrangement, and then // returns true. Due to this reason, the STL function stable_sort // is called before. // ============================================================================ void SSTL_Permutation(const std::string& input, std::vector<std::string>& result) { std::string cs(input); std::stable_sort(cs.begin(), cs.end()); do result.push_back(cs); while(std::next_permutation(cs.begin(), cs.end())); } Wir haben der Funktion eine Containerklasse des Typs std::vector mit den Vektorelementen std::string spendiert. Dieser Container soll unsere generierten Permutationen aufnehmen und verwalten. Er wird als Parameter an die Funktion übergeben. Vor Aufruf der Funktion lässt sich ausreichend Speicherplatz für den Container allokieren, was die Berechnung beschleunigt. Nehmen Sie zur Kenntnis das ein Container der Standard Template Library den Speicher dynamisch verwaltet und die Größe eines vectors begrenzt ist. Die Speicherallokation mit reserve() scheitert, falls die maximale Grenze max_size() überschritten wird. In dem Fall wird eine Ausnahme des Typs length_error oder sogar bad_alloc geworfen. Da die Fakultät ein hohes Wachstum aufweist ist die Größe eines Containers bei zu großen Werten von n nicht mehr ausreichend um die Menge an Daten im flüchtigen Speicher aufzubewahren. Die maximale Größe eines vector In der oben aufgeführten Funktion erzeugt die do while() Schleife alle Permutationen und fügt diese in den vector ein. Nun werden auch lexikographisch unsortierte strings korrekt verarbeitet. Eine weitere Möglichkeit dieses Ziel zu erreichen besteht darin die Standard STL Funktion next_permutation neu zu implementieren, so dass diese auch mit unsortierten strings umgehen kann. Sehen sie sich dazu einfach mal die folgende Implementierung, samt der aufrufenden Funktion ISTL_Permutation an. #include <map> #include <string> #include <vector> #include <algorithm> // generate associative container pair key typedef std::map<char, size_t> POSITION_MAP; // STL: Extended TEMPLATE FUNCTION _next_permutation from algorithm standard header // permute and test for pure ascending, using operator< template<class _BidIt> inline bool _next_permutation(_BidIt _First, _BidIt _Last, POSITION_MAP *pMap/*default=NULL*/) { _BidIt _Next = _Last; if (_First ==_Last || _First == --_Next) return false; for (; ; ) { _BidIt _Next1 = _Next; if (pMap? (*pMap)[*--_Next] < (*pMap)[*_Next1]: *--_Next < *_Next1) { _BidIt _Mid = _Last; for (; !(pMap? (*pMap)[*_Next] < (*pMap)[*--_Mid]: *_Next < *--_Mid);) ; std::iter_swap(_Next, _Mid); std::reverse(_Next1, _Last); return true; } if (_Next == _First) { std::reverse(_First, _Last); return false; } } } // ============================================================================ // Function: ISTL_Permutation // Description: Generate all permuted strings for an input string using // extended STL function _next_permutation(). // Parameter: @input: the input string. // @result: the buffer, where permutations are stored // @bOrdered: flag to set optionally ordering On/Off. // Note: STL next_permutation permutes the string input to the // lexicographically next string as an arrangement, and then // returns true. If the string is in descending order then // it returns false. // ============================================================================ void ISTL_Permutation(const std::string& input, std::vector<std::string>& result, bool bOrdered) { POSITION_MAP mapPos; std::string cs(input); if(!bOrdered) /*default=true*/ for(size_t i = 0; i < cs.length(); i++) mapPos.insert(std::pair<char, unsigned int>(cs[i], i)); do result.push_back(cs); while(_next_permutation(cs.begin(), cs.end(), bOrdered ? NULL : &mapPos)); } Sicherlich erscheint Ihnen diese Lösung etwas umständlicher und ineffizienter. Aber sie ist performancetechnisch der oberen Funktion ungefähr gleichzusetzen. Bis auf die Tatsache das sie aufgrund der Neuimplementierung von next_permutation etwas länger ausfällt. Wie sie nun wahrscheinlich schon erkannt haben, nennen wir diese neue Funktion _next_permutation. Es handelt sich im Prinzip um den originalen STL Algorithmus der ledeglich ein klein wenig modifiziert wurde. Die Funktion ISTL_Permutation() nimmt insgesamt zwei Parameter auf. Zum Einen den input string und zum Anderen das Flag bOrdered, welches es der Funktion ermöglichen soll auch lexikographisch ungeordnete strings in allen Kombinationen auszugeben. Im Default Modus ist das Flag true und die Template Funktion _next_permutation verhält sich wie die Standard-Implementierung aus der STL. Wird allerdings explizit false übergeben, generiert die Funktion auch für unsortierte input strings alle Permutationen. Dazu wird der Code um einen assoziativen Container der Klasse map erweitert. Die Klasse map verwaltet Paare von Schlüsseln und Werten. Mit Hilfe des Schlüssels kann dann eindeutig auf den zugeordneten Wert zugegriffen werden. Der mit typedef vereinbarte Name vereinfacht die spätere Benutzung, ähnlich wie sie es z.B. sicherlich schon von C-Structs her kennen. Sobald das Flag bOrdered false ist (string ist also unsortiert), wird die if() Bedingung ausgeführt und ein Schlüsselpaar, ein sogenanntes pair-key, bestehend aus einem char und einem unsigned int angelegt und in das map-Objekt eingefügt. Im char wird der Buchstabe und im unsigned int dessen Position im string gespeichert. Dieses Paar wird anschließend an _next_permutation() übergeben. Dort führt (*pMap)[*i]<(*pMap)[*j] einen Sortierungsvergleich aus und liefert alle Permutationen zurück. Fertig ist die erweiterte STL Funktion. Permutation mit WiederholungBisher haben wir nur Fälle kennengelernt in welchen die vorliegenden Elemente im string sich nicht wiederholt haben. Zum Beispiel ABC oder 3458 oder monkey. Allerdings kann es auch sein das der string mehrere Elemente gleicher Art beinhaltet. ABBA ist ein Beispiel dafür. Folgende Voraussetzungen gelten für Permutationen mit Wiederholungen.
Berechnet wird die Anzahl an möglichen Permutationen über die Formel:  Der zusätzlich hinzugekommene Faktor k stellt die Anzahl der Wiederholungen eines Elementes dar. Auch hier gilt So existieren beim string ABBA insgesamt 6 Permuationen. Nämlich diese: AABB, ABAB, ABBA, BAAB, BABA, BBAA. Die bisher beschriebenen iterativen Funktionen reagieren unterschiedlich auf diese neue Situation. Während die Funktion SSTL_Permutation alle Permutationen korrekt berechnet, überspringt die ISTL_Permutation Implementierung 2 Permutationen und gibt nur die strings ABBA, BAAB, BABA, BBAA zurück. Hier sollte man also genau differenzieren. Permutation mit Hilfe von RekursionEin relativ oft gegangener Weg Permutationen zu errechnen ist der über die Rekursion. Der Grund hierfür liegt in der Eigenschaft der Fakultät, welche sich hierfür geradezu anbietet. Obwohl die iterative STL Lösung in der Performance deutlich besser als die rekursive Lösung abschneidet, wollen wir auch diese hier auflisten. // ============================================================================ // Function: FREC_Permutation // Description: Generate all permuted strings for an input string // using Recursion // Parameter: @input: the input string. // @result: the buffer, where permutations are stored // @bRepeated: flag to allow optionally element repeat. // ============================================================================ void FREC_Permutation(const std::string& input, std::vector<std::string>& result, bool bRepeated) { std::vector<std::string> v1; std::string s1; char ch; size_t nLen = input.length(); if(nLen == 1) // Base case: Add one-char string result.push_back(input); else { // nLen > 1, need recursion for(size_t i = 0; i < nLen; i++) { ch = input[i]; // Extract each char as the first // To exclude repeated element if (!bRepeated) { size_t j; for (j = 0; j < i; j++) if(ch == input[j]) break; if (j < i) continue; // If i==j, Not a repeated one } s1 = input; // Copy the original string s1.erase(i, 1); // Put the rest string into s1 v1.clear(); // Clear, because we cal this recursively FREC_Permutation(s1, v1, bRepeated); // Recursive for(size_t i = 0; i < v1.size(); i++) { s1 = ch + v1[i]; result.push_back(input); } } } } Die rekursive Lösung verhält sich exakt wie die Funktion SSTL_Permutation wenn das Flag bRepeated false ist. Ist es allerdings auf true gesetzt erzeugt die Funktion FREC_Permutation immer alle Permutationen, unabhängig davon ob sich vereinzelte strings wiederholen oder nicht. Weitere AlgorithmenNeben den bisher gezeigten Algorithmen gibt es noch einen weiteren nennenswerten, von Phillip P. Fuchs geschriebenen Algorithmus, welcher in der Geschwindigkeit und Effizienz mit dem aus der STL gleichzieht und sogar unter gewissen Umständen besser abschneidet. void PHIL_Permutation(const std::string& input, std::vector<std::string>& result) { std::string a(input); int N = a.length(); // constant index ceiling (a[N] length) int ax = N - 1; // constant index ceiling (a[N] length) int *p = new int[N+1]; // target array and index control array int i, j, tmp; // index variables and tmp for swap for(i = 0; i < N+1; i++) // p[N] > 0 controls iteration and index boundary for i p[i] = i; result.push_back(a); i = 1; // setup first swap points to be ax-1 and ax respectively (i & j) while(i < N) { p[i]--; // decrease index "weight" for i by one j = ax - i % 2 * p[i]; // IF i is odd then j = ax - p[i] otherwise j = ax i = ax - i; // adjust i to permute tail (i < j) // set Scope { tmp = a[j]; // swap(a[i], a[j]) a[j] = a[i]; a[i] = tmp; result.push_back(a); } i = 1; // reset index i to 1 (assumed) while (!p[i]) { // while (p[i] == 0) p[i] = i; // reset p[i] zero value i++; // set new index value for i (increase by one) } } delete [] p; } BenchmarkUm die unterschiedlichen Algorithmen in ihrer Performance und Effizienz testen zu können, habe ich einen kurzen Test zum Benchmarken eingebaut. Hier lässt sich deutlich der Unterschied zwischen den unterschiedlichen Algorithmen erkennen. Während die rekursiven Methoden generell deutlich schlechter als ihre iterativen Konkurrenten abschneiden, sind die Methoden "Implemented STL" am schnellsten. Allerdings berechnen nicht alle Algorithmen dieselbe Anzahl an Permutationen. Der nachfolgende Test wurde auf einem P4 mit 2,56GHz und 1024MB RAM durchgeführt.  Die Methode "STL with SORT" erzeugt trotz Sortierung exakt die Hälfte der Permutationen, die beispielsweise Phillip Fuchs liefert. In unserem Beispiel haben wir absichtlich eine Wiederholung eingebaut um den eingangs genannten Unterschied zwischen den Algorithmen zu demonstrieren. Nehmen wir einmal an, wir übergeben die Zeichenkette aba an die Methode "Recursive, Repeated". Das Resultat sähe folgendermaßen aus: aab, aba, aba, aab, baa, baa. Offensichtlich stimmt die Zahl der Permutationen, mit dem bei drei Elementen zu erwartenden Ergebnis überein, sofern man die klassische n! Formel ansetzt. Doch für uns erscheint das Ergebnis doppelt. Die letzten beiden Zeichenketten sind identisch. Das Zeichen a wird vom Algorithmus einfach per Index unterschieden, d.h. für den Algorithmus ist a nicht gleich a. Auch der Algorithmus von Phillip Fuchs berechnet, wie die rekursive Methode, stur alle Elemente im Array ohne auf den Inhalt Rücksicht zu nehmen. Weiterhin bleibt festzuhalten das der Phillip Fuchs im direkten Vergleich geringfügig schlechter als die STL Lösung abschneidet. Insgesamt zeigt sich allerdings das beide Algorithmen äußerst effizient arbeiten, jedoch unterschiedlich bei mehrfach auftretenden Elementen reagieren. Das kurze Konsolenprogramm mit nur 10 Elementen ist letztlich auch nur von bedingter Aussagekraft. Der Großteil der Zeit wird für das Einfügen der Resultate in den vector benötigt und das verlangsamt nicht nur die Berechnungszeit, es limitiert auch die maximale Anzahl von Elementen. Da dieser Schritt allerdings in allen Algorithmen durchgeführt wird, wird das Verhältnis zwischen den Algorithmen nicht verfälscht. Die bloße Berechnung der Permutationen vollzieht sich dementsprechend deutlich rasanter. Sie können den vector bei Bedarf entfernen und nackte Benchmarks durchführen. Das Programm verzichtet bei mehr als 10 Elementen ohnehin auf den vector und nutzt standardmäßig eine Variante des STL Algorithmuses, der die Resultate umgehend in eine Datei schreibt. Beachten Sie allerdings, dass bereits bei 12 unterschiedlichen Elementen die Datei eine Größe von über 5 GB annimmt. SchlussDas war's! Sie finden das Programm samt Quellcode mit den implementierten Algorithmen weiter unten als Visual Studio 2008 gepacktes Projekt vor. Die Permutationen werden in einer Textdatei gespeichert und bis zu einer Stringlänge von 5 auch visuell ausgegeben. |
||||
| Zuletzt aktualisiert am Montag, den 23. April 2012 um 00:23 Uhr |
| AUSWAHLMENÜ | ||||||||
|